Boiling a frog
In 1781, Christian Wilhelm von Dohm, a civil servant, political writer and historian in what was then Prussia published a two volume work entitled Über die Bürgerliche Verbesserung der Juden (“On the Civic Improvement of Jews”). In it, von Dohm laid out the case for emancipation for a people systematically denied the rights granted to most other European citizens. At the heart of his treatise lay a simple observation: The universal principles of humanity and justice that framed the constitutions of the nation-states then establishing themselves across the continent could hardly be taken seriously until those principles were, in fact, applied universally. To all.
Von Dohm was inspired to write his treatise by his friend, the Jewish philosopher Moses Mendelssohn, who wisely supposed that even though basic and universal principles were involved, there were advantages to be gained in this context by having their implications articulated by a Christian. Mendelssohn’s wisdom is reflected in history: von Dohm’s treatise was widely circulated and praised, and is thought to have influenced the French National Assembly’s decision to emancipate Jews in France in 1791 (Mendelssohn was particularly concerned at the poor treatment of Jews in Alsace), as well as laying the groundwork for the an edict that was issued on behalf of the Prussian Government on the 11th of March 1812:
“We, Frederick William, King of Prussia by the Grace of God, etc. etc., having decided to establish a new constitution conforming to the public good of Jewish believers living in our kingdom, proclaim all the former laws and prescriptions not confirmed in this present edict to be abrogated.”
To gain the full rights due to a Prussian citizen, Jews were required to declare themselves to the police within six months of the promulgation of the edict. And following a proposal put forward in von Dohm’s treatise (and later approved by David Friedländer, another member of Mendelssohn’s circle who acted as a consultant in the drawing up of the edict), any Jews who wanted to take up full Prussian citizenship were further required to adopt a Prussian Nachname.
What we call in English, a ‘surname.’
From the vantage afforded by the present day, it is easy to assume that names as we now know them are an immutable part of human history. Since one’s name is ever-present in one’s own life, it might seem that fixed names are ever-present and universal, like mountains, or the sunrise. Yet in the Western world, the idea that everyone should have an official, hereditary identifier is a very recent one, and on examination, it turns out that the naming practices we take for granted in modern Western states are far from ancient.
This fact becomes more apparent when one considers that common German surnames often refer to professions – Müller (miller), or Schneider (tailor) – that are not exactly ancient themselves. Indeed, since Tailor (or Taylor) is also a common English surname, it is worth noting that the Oxford English Dictionary dates the first recorded use of the use of the word “tailor” — anywhere — to the year 1297. And, of course, when viewed with the history of naming practices in mind, names such as Johnson and Jones present themselves as fossils: why are the children of a William Johnson called Johnson rather than Williamson?
As the following passage makes clear, earlier naming practices, such as those found in twelfth and thirteenth century England, were somewhat different to our own:
“A certain Alfwy, who was called Geoffrey as a mark of respect, lord of Wenhaston and Walpole, had two sons by his wife Goda; the eldest, was Geoffrey, known as Geoffrey of Bramfield because he was steward of Bramfield, and the younger, Robert Malet. On the death of their father Alfwy, Geoffrey the firstborn succeeded him, giving Walpole in dower to his mother Goda. His brother Robert entered the service of Earl Hugh and became a knight. Geoffrey, likewise a knight, took a wife and had issue by her a son and three daughters. Unfortunately, whilst still a young man, the son killed a man whom he found embracing his mistress and was forced to flee the country. Distraught, Geoffrey turned to his brother Robert Malet for help, promising him half his land if he could persuade Earl Hugh, then on very good terms with King Henry, to obtain the king’s pardon for his son which was duly done. Afterwards the grateful father gave half of his lands and tenements to his brother Robert Malet, who held them in his lifetime and was succeeded by his son Walter Malet. After the deaths of Geoffrey and his son, his three daughters succeeded to the remainder of his lands. Two of the daughters died and so the inheritance passed to the third, Basilia, who by her husband Ralph of Spexhall, had a son Geoffrey.”
In twelfth century England, the father of Geoffrey of Bramfield might be called Geoffrey of Wenhaston and Walpole. And after Geoffrey One and Geoffrey Two both died, the Geoffreys’ lands might pass on to Geoffrey One’s three daughters, and ultimately – after the death of the sisters – to the eldest son of the youngest daughter who would turn out to be called… Geoffrey.
Meanwhile, although Geoffrey of Wenhaston and Walpole‘s nephew Walter took the patronym Malet because Robert Malet came into possession of half of his elder brother’s properties, had this not happened (suppose Geoffrey Two had not stumbled upon the fateful embrace, and was not otherwise disposed to be a killer), Walter would likely have ended up with a different surname.
Yet by the 19th Century, in large part due to laws relating to the inevitable desire of states to quantify, tax, and occasionally conscript their subjects, native naming systems based on first names – the kind exemplified by the Geoffreys above – had largely been wiped out. In their place, the imposed systems we are familiar with, in which the patronym (the part of the name that sons, wives and daughters inherit from a husband / father) is a fixed “family name” – so that Robert Malets beget Walters who are inevitably called Malet – had been established by law.
Similar patronymic surname systems had also been imposed by legal means across much of Europe, which left the nomadic Ashkenazim – the Yiddish-speaking Jewish population of central and northern Europe – as one of the few hold outs still using a native naming system based on first names. In this case, a typical name was made up of a first name, which was followed by either ben- or bat- (“son of” and “daughter of,” respectively), and then the father’s first name.
To von Dohm, and in all likelihood, the framers of the 1812 edict, the requirement for Jews to adopt a modern style of name was no more than asking them to get with the beat. To the enthusiastic Enlightenment thinker, the state was a good thing. It was the protector of rights, and in striving to impartially uphold the rule of law, keep the peace, settle property disputes, and a host of other similarly good things, states offered to make a previously irrational, brutal and arbitrary existence more rational, secure and predictable. How could the state be a bad thing if, after all, it was the state that was emancipating Jewry?
The political scientist James Scott has described the development of naming systems in which Robert Malet begets Walter Malet begets James Malet as a process of making a population legible to the various bodies that make up a state. As compared to a system in which Robert ben Bill begets Walter ben Robert begets James ben Walter, a patronymic surname system is much easier to read. Which means that if the state – in the person of a judge, a lawyer, or a policeman – wants to be able to establish who James’ grandfather is, the legislation that has imposed specific, formalized naming systems upon most of the world will now make it far more easy to find out than was the case in the past.
If one sees a rational, enlightened state as a good thing – and it seems clear that von Dohm, Mendelssohn and most like-minded contemporaries did think this – then making a society as legible to the state as possible must be a good thing too. The idea that Jewish families should have modern, legible names appeared to be no more than a minor detail, a small part of the larger, inevitable process of developing modern nation states for the common good.
And this process did appear inevitable: On 23 July 1787, five years after publishing his own Edict of Jewish Tolerance, Austrian Emperor Joseph II issued Das Patent über die Judennamen, which ordered:
“that amongst all of the Jews of all of the provinces, each householder for his family, each guardian of orphans, and each unmarried man no longer under the custody of his father, shall, by the January 1st 1788, adopt a definite name. Unwed women shall take their father’s name, married women shall take the name of their husband; every person, without exception, is obliged to take a German surname, and to keep it for life.”
In Prussia, the city of Breslau issued a similar order in 1790, which was then applied to the city’s administrative region in 1791; the region of Liegnitz followed in 1794. As in much of Europe at this time, for the most part these orders were small aspects of much larger plans aimed at bringing the Jewish population to full citizenship.
Yet, as time went by, the motives of – or at least, the messages sent out by – lawmakers became murkier. In Prussia, the 1812 edict had made the adoption of surnames a requirement for those seeking citizenship. But when a law replacing it was issued on the 22nd of December 1833, all Jews were now required to adopt German surnames. And it was now no longer enough for Jews to simply to adopt some form of German surname: These names now had to be taken from a list that the government had drawn up (Himmelblau, Rubenstein, Bernstein, Hirsch, Loew, etc.). A law passed in 1845 then turned this into a closed list, while also requiring that the names previously adopted by the Jewish population be changed to conform with this new standard.
Finally, on 12 July 1867, district presidents were empowered with reviewing and confirming the name changes that came about when members of the Jewish faith converted to Christianity. Even after conversion, the origins of Jewish citizens would still be coded for in their surnames. In the words of the German linguist, Dietz Bering, “the Jews, for whom in 1812 the gates of the legal ghetto had been opened only half-heartedly and not even completely, were to be imprisoned again in another ghetto: one of names.”
What had, to a large extent, begun as a modern, liberal minded attempt at the imposition of universal values had turned into something more sinister. And when, in time, the Nazi state implemented its Final Solution, “the closed list of Jewish patronyms made the task of genocide terrifyingly simple.”
Never say never
Sticks and stones may break my bones
But names will never hurt me.
As the foregoing suggests, names can prove to be far more malign than the old nursery rhyme would have us believe. The question is, how much more? Does the imposition of surnames on Europe’s Jews represent a historical one-off? Or are some people enslaved by their names even today? In 2001, economists Marianne Bertrand and Sendhil Mullainathan began to examine this last question by sending out thousands of resumés in response to the job ads posted in the Boston Globe and the Chicago Tribune over a two year period. Bertrand and Mullainathan weren’t looking for work; rather, they wanted to know whether the simple presence of an African-American-sounding name on a resumé would have a negative influence on its impact.
To get at this question, Bertrand and Mullainathan hit upon the idea of sending out fictitious resumés. The name at the top of each resumé was manipulated so as to make it more African-American– or White-sounding, and — in what I think was a piece of genius — to measure success, Bertrand and Mullainathan recorded the rate at which these otherwise identical applications got a callback from an employer.
What they discovered was startling: if a White-sounding name was on a resumé, potential employers were 50% more likely to call back than if an African-American-sounding name was on it. Moreover, while putting a White-sounding name on a higher-quality resumé generated a 30% boost in a fictitious applicant’s chances of getting a callback over a lower-quality resumé, when it came to African-American sounding names, this boost dropped to just 9%.
Bertrand and Mullainathan’s paper, “Are Emily and Brendan More Employable than Lakisha and Jamal?” is now a classic, and their results, which have been taken to demonstrate just how subtle the effects of racial bias can be, are cited everywhere, from the popular press to the Supreme Court. However, while I’ll admit to being biased in advance to accept the findings of this study, something has always bothered me about it: Whatever the relative employability of Emily and Brendan, isn’t it also the case that their latter names are more common than Lakisha and Jamal?
Here’s the problem: it isn’t that Bertrand and Mullainathan (and thankfully, the Supreme Court) were unaware that the choice of names is crucial to an experiment like this. They realized that in order to be sure that implicitly perceived race was prompting the bias in their results, they should try to ensure that the names they chose were matched on their other dimensions, such as frequency. Accordingly, to find suitable names that were distinctively White or distinctively African-American, the authors tabulated the male and female names that appeared both frequently and distinctively in each group in Massachusetts birth certificates from 1974 to 1979.
This is the set of the names they ended up with:

However, while these names might be matched for the frequency at which they occurred in Massachusetts birth registrations, it seemed to me that raw counts taken from birth records in the 70’s might not be the best way of way of controlling for what I was worried about – which is the relative familiarity of these names to potential employers.
Consider the fact that John F Kennedy died before I was born: It remains the case that I’m very familiar with his name; And although recent birth records in the US reveal that John hasn’t been a wildly popular name for a while now, this doesn’t mean that there aren’t a goodly number of Johns already out there, or that John might not be a more familiar name to me than many names that have now become more popular with parents. Indeed, it seems likely that the total set of existing Johns will still be still far larger than that of many names that have now trumped John in popularity. Similarly, it doesn’t seem that an estimate based on current birth rolls can allow us to control for the historical popularity of John. John was, in fact, the most common male name in English for centuries, and by dint of this, a large number of outstanding Johns have had the opportunity to be selected for fame over time, such that the first name of these famous Johns has been drummed even more deeply into the collective consciousness as a result.
It was the effect of this consciousness drumming that I was bothered about, and unfortunately, Bertrand and Mullainathan’s methods couldn’t help me. I should emphasize at this point that this is not a criticism of their work. At the time they did this work, estimating the frequencies for this kind of thing was barely feasible, even for data scientists. Yet today these kind of big data counts are easy to obtain (the problems one now faces are more to do with figuring out what, exactly, to count). And since COCA, the 450 million word Corpus of Contemporary American English, just happens to cover the period 1990-2012, and since Bertrand and Mullainathan’s study was conducted bang in the middle of that period, it seemed to me that this would be as good a place as any to start trying to estimate how familiar the names Emily, Brendan, Lakisha, and Jamal might be to anyone reading a resume.
Are Emily and Brendan more familiar than Lakisha and Jamal?
The following graph plots (on the vertical axis) the rates at which the female names studied by Bertrand and Mullainathan appear in COCA:

What is clear from these counts is that when it comes to everyday American English, most people are far more likely to read and hear Bertrand and Mullainathan’s White-sounding female names than they are their African-American-sounding counterparts.
The next graph shows that this also turns out to be true for the male names:

Why does this matter? Well, many years ago an old colleague of mine, Bob Zajonc, showed that frequency, or as he put it, “mere exposure” exerts a surprisingly strong influence on people’s attitudes. Despite the supposed common wisdom enshrined in sayings such as familiarity breeds contempt, or absence makes the heart grow fonder, Zajonc’s work shows that, in fact, the mere act of being repeatedly exposed to a stimulus enhances people’s attitude toward it, and that the more that people are exposed to words, the more positive they tend to feel about them. (It’s actually slightly more complicated than that, and I’ll come back to this point in my next post.)
Zajonc’s findings inspired the psycholgists Andrew Colman, David Hargreaves and Wladyslaw Sluckin to try to find out whether the mere exposure effect also applied to people’s names. So Colman, Hargreaves and Sluckin got people in both the UK and Australia to rate 100 randomly selected male or female English first names for familiarity (how commonly they felt they encountered them), or how favorable their attitude to each name was. The plots below, in which familiarity is plotted horizontally, and favorability is plotted vertically, are taken from the report that describes what they found:

In both countries, and for both male and female first names, they found that favorability judgments increase reliably as familiarity rises, meaning that if someone is familiar with a name, then they are likely to feel more favorable towards it as well. It is worth emphasizing here that Colman et al. used a between-subjects design in this study: subjects rated the names for either familiarity or favorability, which allows us to rule out the possibility that making the familiarity judgments influenced people’s favorability ratings. (And, as will become clear in a moment, while the relationship was strong for both male and female names, the effect was strongest for male names.)
Colman et al were forced to use subjective ratings of familiarity in their study because, as I mentioned earlier, data resources like COCA have only recently become available to researchers. Yet since Colman et al’s study shows that subjective ratings of familiarity clearly do predict favorability, it becomes interesting to ask whether objective frequency counts do as well. If we assume, as Bertrand and Mullainathan did, that the differences in callback rates reflect the way that employers responded to the names atop those resumés, then it seems like a good idea to see whether “mere familiarity” might also be at work here.
So, to test these ideas, I calculated the correlation between the the COCA frequencies and the callback rates for the sets of names used by Bertrand and Mullainathan. (Because there’s reason to suppose that gender might also play in favorability judgments, I followed Colman et al’s lead, and calculated this relationship separately for male and female names; and as ever, I log transformed the data to take account of the skew that is invariably associated with linguistic data.)
This graph plots the relationship between frequency and callback rates for all of the female names:

It shows that around 60% of the variation in the callback rates for females found in Bertrand and Mullainathan’s study can be explained by the frequency differences in the names they studied. Here’s what the same relationship looks like for the male names:

showing that around 45% of the variation in male callback rates can also be explained by the objective frequencies of this particular set of names.
In Colman, Hargreaves and Sluckin’s study of favorability and familiarity, the correlation between subjective familiarity and favorability was r=.82 for male names and r=.67 for female names, wheras the correlation between objective linguistic frequency and the callback rates in Bertrand and Mullainathan’s study are r=.68 for male names and r=.79 for female names, respectively. What this means is that the effects of subjective and objective familiarity appear to be at least roughly comparable, and that around half of the variability in callback rates that Bertrand and Mullainathan found for males in their study, and nearly two thirds of the variability for females, can be accounted for by the relative familiarity of the first names that were attached to those fictitious resumés.
Full names
Since it seems fairly clear that familiarity is playing a role here, we can now turn our attention to an aspect of the study that I’ve so far ignored: The last names that Bertrand and Mullainathan used to make their fictitious resumés complete. Here are the sets of the White and African-American-sounding surnames used in the study, along with their COCA frequencies (there are different numbers in each set, because that’s what Bertrand and Mullainathan reported using):

What’s immediately striking is that the African-American-sounding surnames (in blue) are far more frequent on average than the White-sounding surnames (in red).
This difference becomes particularly interesting when considered together with this next plot, in which I’ve taken US Census data for the top 200 male first names (red), female first names (blue) and last names (green), and plotted them according to the percentage of the US population that has one of them:
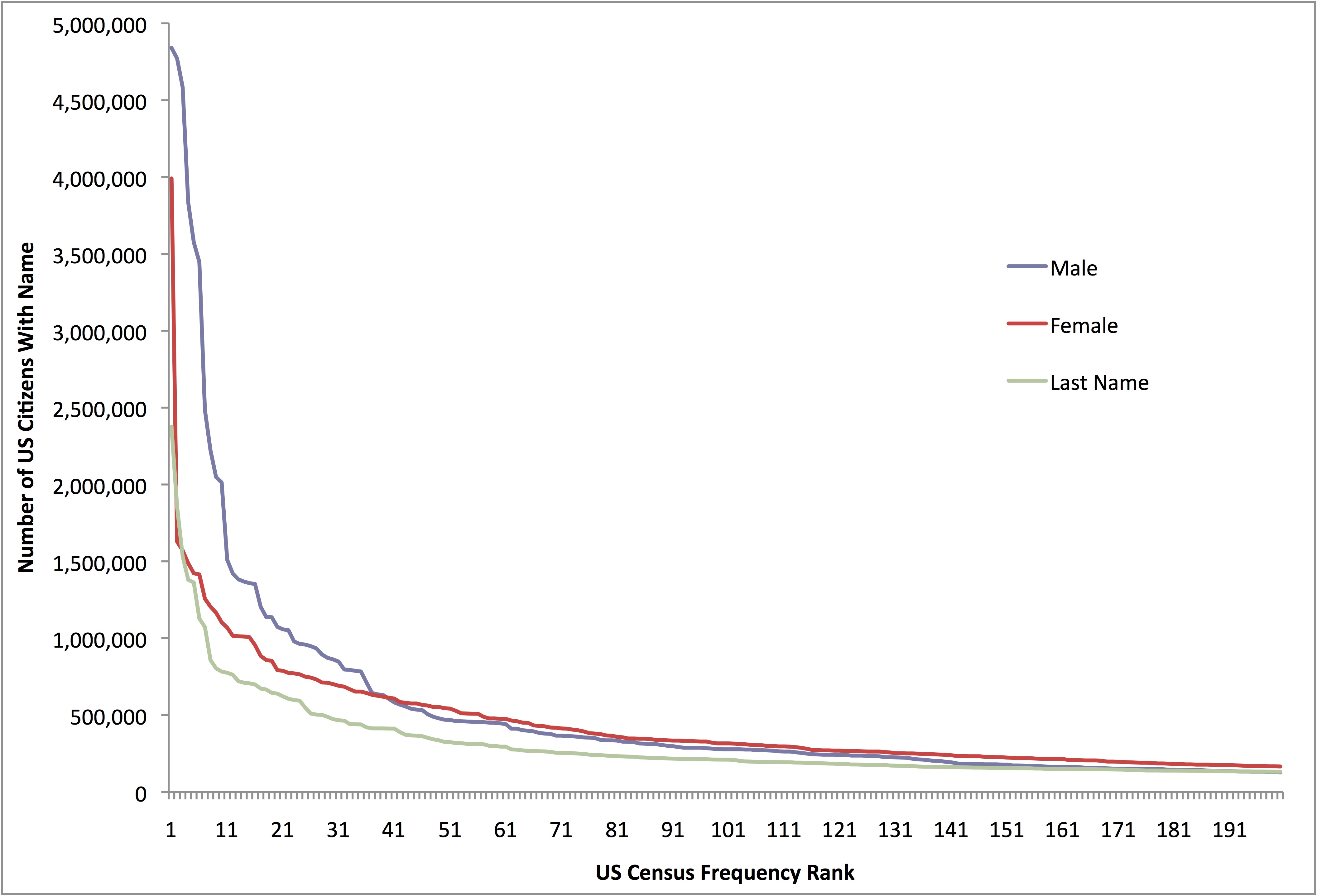
It turns out that in the United States, 72.5% of the male population has one of the most common 200 male names, and 58% of females have one of the most common 200 female names. By contrast, only 23% of the population as a whole has one of the 200 most common last names. (As this plot also illustrates, name distributions – like any other aspect of language – are Zipf distributed.)
In other words, Americans share far more first names than they do last names. Which in turn indicates that an American name typically comprises a first name that is more common than its last name. Or, to say this another way, the names Americans tend to hear and use day in and day out, tend to have a first name attached that’s a lot more frequent than the surname that follows. So, if we take the archetypal male name, John Smith, Census data tells us there are more than twice as many Johns in America as there are Smiths, and the COCA frequency of John is actually three times greater than that of Smith. (As I mentioned earlier, the frequency with which we talk about things – such as dead presidents – won’t necessarily match up with their actual rate of occurrence in the world).
So this is what we see when go back and look at the average COCA frequencies of the first and last names used by Bertrand and Mullainathan:

In every case – for both the White- and the African-American-sounding names – the first names used in the study occur on average far less frequently in English than the last names.
And what this means is that, as far as full American names go, none of the names Bertrand and Mullainathan used in their study were really very typical (or particularly familiar) at all. However, what is also abundantly clear is that the full African-American-sounding names they selected – which have extremely low frequency first names and extremely high frequency last names – are a good deal further from the prototypical American name than are the full White-sounding names.
In other words, not only are Lakisha and Jamal’s first names far less familiar than Emily and Brendan’s, but when taken as a whole, Lakisha and Jamal’s full names are far less typical (and hence, familiar) than those of Emily and Brendan. As I’ll show later, this turns out to be important.
But before I do that, I want to show you how confusing all these issues can get if we ignore the fact that names are made up of more than one part.
What is atypical about Lakisha and Jamal?
While Bertrand and Mullainathan’s study clearly seems to support the idea that the name placed atop a resumé can exert a powerful effect on its chances of success, Freakanomics author Steven Levitt and economist Roland Fryer Jr. think otherwise. After studying data for every child born in California over a four-decade period, Levitt and Fryer argued that they could see little evidence that a person’s having a distinctively black name actually had a negative impact on their eventual life outcome. They argue that it is not having a distinctively African-American first name that results in worse economic outcomes in adulthood. Rather, they note that African-American babies born in more affluent – and more diverse neighborhoods – tend to be given names that are less noticeably African-American than babies born in poorer, more segregated neighborhoods, and that as such, possession of a more African-American first name indicates that someone comes from a worse socioeconomic background.
Levitt and Fryer argue that employers infer productivity from ethnic names – i.e., employers don’t infer that Jamal is African-American, but rather that he comes from a poor background – and suggest that, “the stark differences in naming patterns among blacks and whites is best explained as a consequence of continued racial segregation and inequality, rather than a cause that is perpetuating these factors.”
Levitt and Fryer’s paper, The Causes And Consequences Of Distinctively Black Names, argues that what causes parents to give their children distinctively African-American first names is poverty (and being Black), and that a consequence of this is that it helps keep those children in poverty. Hence Levitt and Fryer suggest that the proper interpretation of Bertrand and Mullainathan’s study is, “either that the impact of names does not extend beyond the callback decision (because race is directly observed at the interview stage), or that names are correlated with determinants of productivity not captured by a resumé.”
The idea that one’s chances of getting an interview has no impact on one’s chances of getting a job seems a strange one to me, as does the idea that one’s qualifications don’t somehow reflect one’s productivity up to the point that one’s resumé was compiled. But there is more wrong with the Levitt and Fryer paper than these rather odd conclusions. First, they confuse absence of evidence – not finding an effect – with evidence of absence – concluding that since their way of looking revealed nothing, there is therefore nothing to show.
Second, in the course of essentially blaming poor parents for impeding their children’s life chances – without ever explaining why, exactly, it is that poverty leads African-American parents to choose to call their children Lakisha and Jamal – Levitt and Fryer fail to take account of the skew of linguistic data, and as a result, hugely distort the data that they’re analyzing.
For example, if secondary sources are anything to go on, one quantitative point from Levitt and Fryer’s paper has had a massive impact, as it is invariably repeated in some form whenever their study is discussed:
“Even among popular names, racial patterns are pronounced. Names such as DeShawn, Tyrone, Reginald, Shanice, Precious, Kiara, and Deja are quite popular among Blacks, but virtually unheard of for Whites.* The opposite is true for names like Connor, Cody, Jake, Molly, Emily, Abigail, and Caitlin. Each of those names appears in at least 2,000 cases (between 1989-2000), with less than two percent of the recipients Black…
* There are 463 children named DeShawn, 458 of whom are Black. The name Tyrone is given to 502 Black boys and only 17 Whites. 310 out of 318 Shanice’s are Black, as are 431 out of 454 girls named Precious, and 591 out of 626 girls named Deja.”
Taken at face value, these numbers imply that African-American parents behave more extremely than other parents in their naming decisions. Indeed, framed like this, the suggestion is that African-American parents are minded to give their children extremely rare names, such as Shanice (in contrast to parents from other ethnicities, who tend to stick to more conservative names, like Molly), a behavior that is apparently widespread. It is thus sobering to note that in the period from which these numbers are taken, even if we were to add together all of the babies given the names Tyrone, Deshawn, Shanice, and Precious – which Levitt and Fryer tell us are ‘popular’ among African-Americans – it turns out that the number of African-American babies given these names comes to less than 5 out of every 1000 born during this time.
Or, say we take the rarest of the African-American names that Levitt and Fryer picked out, Shanice, and look more closely at the underlying figures. It turns out that while it’s true that 83 out of every 100,000 African-American babies was named Shanice, the low absolute number of Shanices quoted by Levitt and Fryer is a direct consequence of the fact that African-American babies represent only around 6% of the total born in California each year. And there’s a flipside to this. When it comes to the non African-American babies who wound up with the names Connor, Cody, Jake, Molly, Emily, Abigail, and Caitlin, it turns out that each of these names was given to only around 64 out of every 100,000 babies in this group. In other words, it turns out that a greater proportion of African-American babies were named Shanice than non-African-American babies were named Connor, Cody, Jake, Molly, Emily, Abigail, or Caitlin.
This reflects a simple consequence of something we saw earlier: If it turns out that almost three-quarters of American men share just 200 names, and if those names are just like any other part of language and Zipf distributed, then it follows that the names of people who fall outside of this group will, by definition, be rare. And it gets us back to the (rather obvious) fact that there is more to an American name than John or DeShawn alone: As well as having (at least) one first name, Americans – like most people in most cultures these days – also have a last name, and all the parts of a person’s name, both individually and jointly, convey information that can affect how favorably their name is received, whether by an employer, or anyone else.
That this story is about more than just first names is made clear in the following graph. It plots the frequency of the full names used by the economists John Nunley, Adam Pugh, Nicholas Romero, and Alan Seals in a recent follow-up to Bertrand and Mullainathan’s study. Nunley et al sent out resumés for fictitious graduates response to ads for professional jobs (obtaining a similar pattern of results as Bertrand and Mullainathan). In the plot, the 4 White-sounding names used in this study (Cody Baker, Jake Kelly, Claire Kruger, and Amy Rasmussen) are on the left, and the 4 African-American-sounding names (Ebony Booker, Aaliyah Jackson, Deshawn, Jefferson, and Deandre Washington) are on the right. The front row of columns represent the log COCA frequencies of the fictitious first names, and the back row represents the log COCA frequencies of the fictitious last names:

Just as in Bertrand and Mullainathan’s study, it is clear that it isn’t only that the African-American-sounding first names are less frequent than their White sounding counterparts. It is also that the African-American-sounding names, which – once again, were associated with far fewer callbacks than the White-sounding names – are structurally different, with both higher frequency last names and lower-frequency first names.
All of which raises a number of questions. Since most parents don’t choose their children’s last names, what is going on? Why do full African-American-sounding names tend to have one structure, and full White-sounding names another? Why doesn’t the relative familiarity of an African-American-sounding last name counterbalance the relative unfamiliarity of an African-American-sounding first name? And what could this tell us about the different naming patterns Levitt and Fryer observed amongst more- and less-integrated African-Americans?
To answer them, in my next post, I’m going to do something that none of the studies discussed so far have done. I’m going to step back and ask: What are names anyway? What do they do? And where did they – and these differences – come from?
![]()
Bertrand, M., & Mullainathan, S. (2004). Are Emily and Greg More Employable Than Lakisha and Jamal? A Field Experiment on Labor Market Discrimination American Economic Review, 94 (4), 991-1013 DOI: 10.1257/0002828042002561
Colman, A., Hargreaves, D., & Sluckin, W. (1981). Preferences for Christian names as a function of their experienced familiarity British Journal of Social Psychology, 20 (1), 3-5 DOI: 10.1111/j.2044-8309.1981.tb00465.x
Fryer, R., & Levitt, S. (2004). The Causes and Consequences of Distinctively Black Names The Quarterly Journal of Economics, 119 (3), 767-805 DOI: 10.1162/0033553041502180
Nunley, J.M., Pugh, A., Romero, N., & Seals, R.A. (2014). An Examination of Racial Discrimination in the Labor Market for Recent College Graduates: Estimates from the Field Auburn Economics Working Paper Series
Zajonc, R. (1968). Attitudinal effects of mere exposure. Journal of Personality and Social Psychology, 9 (2), 1-27 DOI: 10.1037/h0025848
